Compiler Design
Compilers are fundamental to computing. Every language from C to Rust depends on a compiler to translate human-readable code into machine-executable instructions. By understanding how compilers work, you can stop guessing and start knowing exactly what happens under the hood.
Follow this roadmap in order if you’re starting from zero:
- Formal Languages & Automata
- Lexical Analysis
- Parsing
- Abstract Syntax Trees
- Semantic Analysis
- Intermediate Representation
- Code Generation
- Optimization
1. Formal Languages & Automata
This branch of computer science studies which problems computers can solve, how they solve them, and how efficiently they can do so.
1.1 Symbol
A symbol is the smallest, indivisible building block of a formal language (e.g., a letter, a digit, or a special character like a, 0, or #).

1.2 Alphabet (Σ)
An alphabet (denoted by Σ) is a finite, non-empty set of symbols. It defines the “vocabulary” available for creating strings. For example, the binary alphabet is Σ = {0, 1}.

1.3 String
A string is a finite sequence of symbols chosen from some alphabet. A string is generally denoted as w, and the length of a string is denoted as |w|. The empty string is a string with zero occurrences of symbols, represented as ε.
Number of Strings (of length 2) that can be generated over the alphabet {a, b}:
| 1st symbol | 2nd symbol |
|---|---|
| a | a |
| a | b |
| b | a |
| b | b |
Length of String |w| = 2
Number of Strings = 4
Conclusion:
For alphabet {a, b} with length n, number of strings can be generated = 2^n.
1.4 Language
- A language is a set of strings formed using the symbols of a given alphabet Σ.
- Formally, a language is a subset of Σ*, where Σ* is the set of all possible strings (including ε) over the alphabet Σ.
Examples of Languages:
Finite Language:
L1 = { set of strings of length 2 }
L1 = { xy, yx, xx, yy }
Infinite Language:
L2 = { set of all strings starting with 'b' }
L2 = { b, ba, bb, baa, bab, bba, bbb, ....... }1.5 Operations on Languages
Just as arithmetic has addition and multiplication, languages have their own formal operations.
1. Union ( L1 ∪ L2 )
Combine all strings from both languages.
L1 = { aa, ab }
L2 = { b, bb }
L1 ∪ L2 = { aa, ab, b, bb }2. Concatenation ( L1 · L2 )
Attach every string of L1 with every string of L2.
L1 = { a, b }
L2 = { x, y }
L1 · L2 = { ax, ay, bx, by }Take one from L1, stick one from L2 behind it. Do for all combinations.
3. Kleene Star ( L )*
Zero or more repetitions of strings from L. Always infinite. Always includes ε.
L = { a, b }
L* = { ε, a, b, aa, ab, ba, bb, aaa, aab, ... }Positive Closure ( L+ ) = same but without ε
L+ = { a, b, aa, ab, ba, bb, aaa, ... }1.6 Chomsky Hierarchy
The Chomsky Hierarchy is a classification of formal languages into four types based on the restrictions of their grammars and the computational power required to recognize them. It covers all language types, from regular languages (Type 3) with the simplest grammar to recursively enumerable languages (Type 0) with the most complex grammar.
| Type | Name | Recognized by |
|---|---|---|
| Type 0 | Unrestricted | Turing Machine |
| Type 1 | Context Sensitive | Linear Bounded Automaton |
| Type 2 | Context Free | Pushdown Automaton |
| Type 3 | Regular | Finite Automaton (DFA/NFA) |
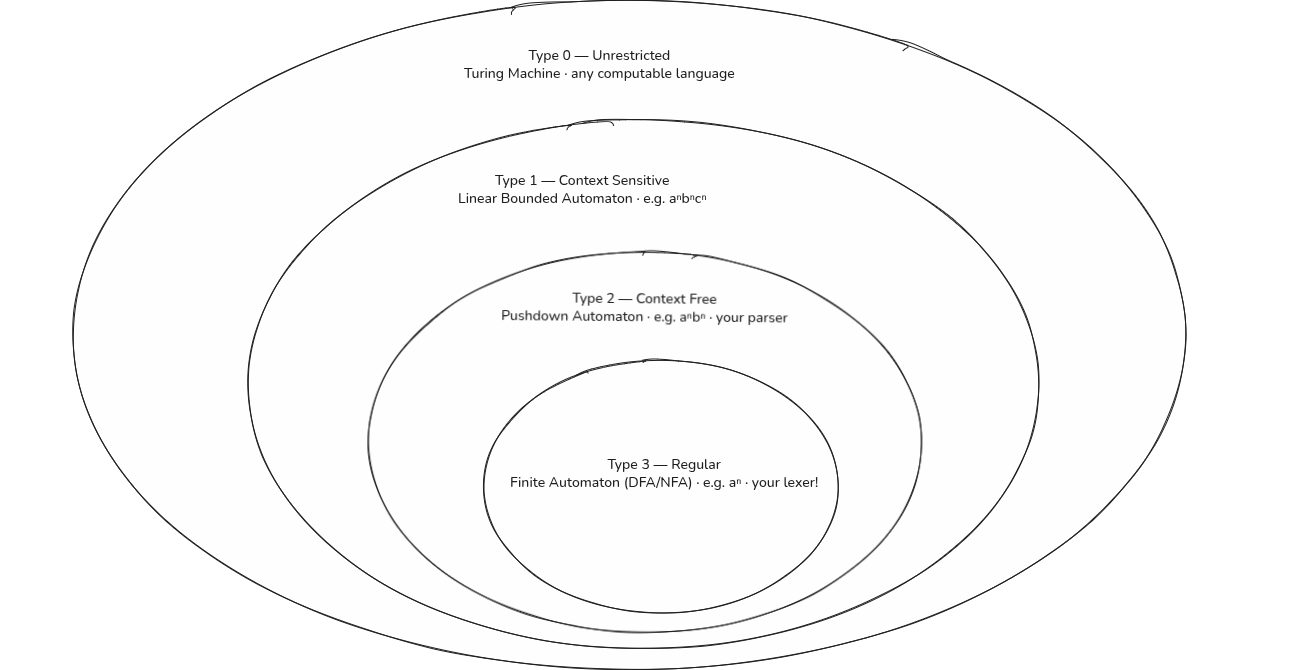
The grammar types are explored below. (Note: The table above lists them from Type 0 to Type 3 (unrestricted to most restricted), but we will explore them below in reverse order, starting from the most restricted (Type 3) and moving to unrestricted).
Type 3: Regular Grammar
- Recognized by: Finite State Automaton (DFA/NFA) (This is the engine for your Lexer!)
- Description: Type-3 grammars generate regular languages. It is the most restricted form of grammar.
- Production Rules: Productions must be in the form
A → aBorA → a(right-regular), orA → BaorA → a(left-regular), whereA,Bare variables andais a terminal. - Example:
S → a
Type 2: Context-Free Grammar
- Recognized by: Pushdown Automaton (PDA) (This is the engine for your Parser!)
- Description: Generates context-free languages. It can handle nested structures which are essential for defining programming language syntax. Every Type-2 grammar must also be a Type-1 grammar.
- Production Rules: The left-hand side can have only one variable, and there is no restriction on the right-hand side (
|α| = 1). - Example:
S → AB,A → a,B → b
Type 1: Context-Sensitive Grammar
- Recognized by: Linear Bounded Automaton (LBA)
- Description: Generates context-sensitive languages. It must first satisfy Type-0 conditions.
- Production Rules: The number of symbols on the left-hand side must be less than or equal to the number of symbols on the right-hand side (
|α| <= |β|). - Example:
S → AB,AB → abc,B → b
Type 0: Unrestricted Grammar
- Recognized by: Turing Machine
- Description: Includes all formal grammars, generating Recursively Enumerable languages. It represents any computable language.
- Production Rules: There is no restriction on the right side. The only requirement is that there must be at least one variable on the left side (
α → β). - Example:
SAb → ba,A → S
1.7 Regular Expressions
A regular expression (regex) is a pattern that describes a set of strings. It serves as a compact syntax for writing a Regular Language (Type 3).
Basic Symbols
| Symbol | Meaning | Example |
|---|---|---|
| a | literal character | a → { a } |
| ε | empty string | ε → { ε } |
| ∅ | empty language | ∅ → { } |
| . | any single character | . → { a, b, c, … } |
| [abc] | any one of a, b, c | [abc] → { a, b, c } |
| [a-z] | range a to z | [a-z] → { a, b, … z } |
| [^abc] | anything except a, b, c | [^abc] → { d, e, f, … } |
Operations
| Operation | Symbol | Meaning | Example |
|---|---|---|---|
| Union | a | b | a or b |
| Concatenation | ab | a then b | ab → { ab } |
| Kleene Star | a* | zero or more | a* → { ε, a, aa, … } |
| Positive Closure | a+ | one or more | a+ → { a, aa, aaa, … } |
| Optional | a? | zero or one | a? → { ε, a } |
| Grouping | (ab) | treat as unit | (ab)* → { ε, ab, abab, … } |
| Exactly n times | a{n} | exactly n copies | a{3} → { aaa } |
| At least n times | a{n,} | n or more | a{2,} → { aa, aaa, … } |
| Between n and m | a{n,m} | n to m copies | a{2,4} → { aa, aaa, aaaa } |
Shorthand Classes
| Symbol | Meaning | Equivalent |
|---|---|---|
| \d | any digit | [0-9] |
| \D | any non-digit | [^0-9] |
| \w | word character | [a-zA-Z0-9_] |
| \W | non-word character | [^\w] |
| \s | whitespace | [ \t\n\r] |
| \S | non-whitespace | [^\s] |
Anchors
| Symbol | Meaning |
|---|---|
| ^ | start of string |
| $ | end of string |
| \b | word boundary |
| \B | non-word boundary |
Precedence (high to low)
| Priority | Operation |
|---|---|
| 1 (highest) | Grouping ( ) |
| 2 | Kleene Star *, +, ?, { } |
| 3 | Concatenation ab |
| 4 (lowest) | Union a |
1.8 Finite Automata
Finite automata are the execution engines that recognize Regular Languages. They provide the mathematical, state-tracking mechanism required to power Lexical Analysis in modern compilers.